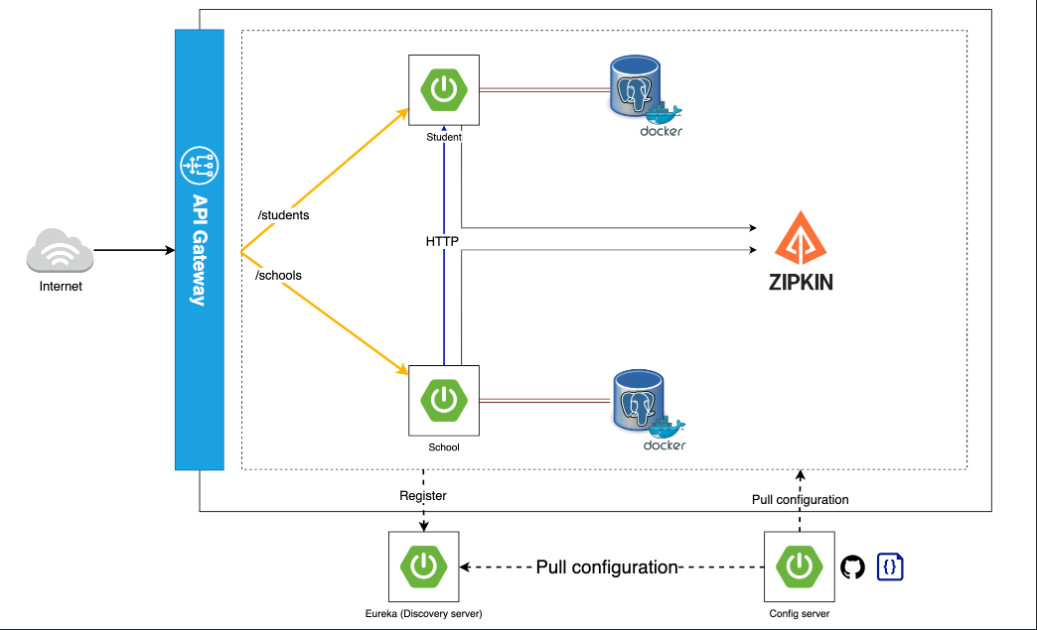
Spring Boot Microservice Architecture
👋 Hey there! I’m Shohanur Rahman!
I’m a backend developer with over 5.5 years of experience in building scalable and efficient web applications. My work focuses on Java, Spring Boot, and microservices architecture, where I love designing robust API solutions and creating secure middleware for complex integrations.
💼 What I Do Backend Development: Expert in Spring Boot, Spring Cloud, and Spring WebFlux, I create high-performance microservices that drive seamless user experiences. Cloud & DevOps: AWS enthusiast, skilled in using EC2, S3, RDS, and Docker to design scalable and reliable cloud infrastructures. Digital Security: Passionate about securing applications with OAuth2, Keycloak, and digital signatures for data integrity and privacy. 🚀 Current Projects I’m currently working on API integrations with Spring Cloud Gateway and designing an e-invoicing middleware. My projects often involve asynchronous processing, digital signature implementations, and ensuring high standards of security.
📝 Why I Write I enjoy sharing what I’ve learned through blog posts, covering everything from backend design to API security and cloud best practices. Check out my posts if you’re into backend dev, cloud tech, or digital security!

Monolithic Vs Microservice
| Feature | Monolithic Architecture | Microservices Architecture |
| Structure | Single codebase | Multiple independent services |
| Deployment | Deployed as a whole | Deployed independently |
| Scalability | Scales vertically (adding more resources to a single server) | Scales horizontally (adding more instances of individual services) |
| Complexity | Simpler to develop and manage initially | More complex to develop and manage |
| Maintainability | Changes to one part can impact the entire application | Changes to one service are isolated from other services |
Some Terminology
Before moving forward we need to know some terminology.
Api Gateway
API gateway acts as a centralized control point for managing Application Programming Interfaces (APIs). It sits between client applications and backend services, like a traffic controller for API requests. Here's a breakdown of its key functions:
Single entry point: It provides a single URL for clients to access all the APIs offered by a system, simplifying integration and reducing complexity.
Routing: It directs incoming API requests to the appropriate backend service based on defined rules, ensuring requests reach the intended destination.
Security: It enforces security policies such as authentication, authorization, and throttling to protect APIs from unauthorized access and abuse.
Traffic management: It helps manage traffic flow by distributing requests among multiple backend services for improved performance and scalability.
Monitoring and analytics: It provides insights into API usage patterns, allowing developers to identify and address potential issues.
Config Server
A config server acts as a centralized repository for managing configuration properties across all your microservices. This offers several benefits:
Simplified configuration management: Instead of managing configuration files individually in each microservice, you store them in a central location, making updates easier and more consistent.
Environment-specific configurations: You can define different configuration sets for different environments (e.g., development, test, production) within the config server, allowing targeted adjustments based on the environment.
Dynamic configuration updates: Microservices can dynamically refresh their configurations without requiring a restart, enabling quick adaptation to changes.
Here's a breakdown of how it works:
Config server: This is a dedicated Spring Boot application with the
@EnableConfigServerannotation. It typically stores configurations in sources like Git repositories, databases, or cloud storage.Config client: Each microservice includes the
spring-cloud-starter-configdependency and is configured to point to the config server.Fetching configurations: During startup, the config client fetches its specific configuration from the server based on its application name and profile (e.g.,
service-name-dev.properties).Dynamic updates: The config client can periodically check for updates or be triggered to refresh, allowing it to adopt new configurations without restarting the service.
Discovery Server
A discovery server, also known as a service registry, plays a crucial role in microservices architectures by enabling service discovery. Here's a breakdown of its key functions:
Service registration: Microservices register themselves with the discovery server by providing information like their name, location (IP address and port), and health status.
Service lookup: Client applications or other services can query the discovery server to find the location of specific services they need to interact with.
Dynamic service updates: The discovery server tracks changes in service availability (e.g., a service going down or coming back online) and updates its registry accordingly. This ensures clients always connect to healthy and available instances of the services they need.
Benefits of using a discovery server:
Simplified service discovery: Clients don't need to hardcode the location of services, making them more flexible and adaptable to changes in the environment.
Improved scalability: Discovery servers enable horizontal scaling, where you can add more instances of a service to handle increased load. The discovery server automatically directs requests to the available instances.
Fault tolerance: If a service becomes unavailable, the discovery server can redirect clients to other healthy instances, improving the overall resilience of the system.
Common discovery server implementations:
Consul
Eureka
ZooKeeper
Load Balance
Load balancing, in the context of computing, is the process of distributing workloads across multiple servers or resources to optimize performance, scalability, and fault tolerance. Imagine a busy restaurant with a single cashier. During peak hours, the cashier gets overwhelmed, leading to long wait times for customers. Load balancing is like adding more cashiers to handle the increased customer flow, ensuring everyone gets served efficiently.
Here's how load balancing works:
Clients send requests: Clients (e.g., users browsing a website) send requests to a central point, often called a load balancer.
Load balancer distributes requests: The load balancer acts as a traffic cop, analyzing factors like server health, workload, and predefined algorithms to choose the most suitable server for each incoming request.
Server processes request: The chosen server receives the request, processes it, and sends back the response to the client.
Fault Tolerance
Fault tolerance in microservices refers to the system's ability to continue operating as expected in the face of failures or faults within individual components or services. Since microservices architecture involves breaking down an application into smaller, independently deployable services, each service is prone to failures such as network issues, hardware failures, software bugs, or human errors. Fault tolerance mechanisms are crucial for ensuring the reliability and availability of the entire system despite these potential failures.
Here are some common approaches to achieving fault tolerance in microservices:
Redundancy: Running multiple instances of the same service in different environments or on different servers to ensure that if one instance fails, another can take over seamlessly. This can be achieved using load balancers to distribute traffic across multiple instances.
Circuit Breaker: Implementing a circuit breaker pattern to detect failures and prevent cascading failures. When a service encounters a failure, the circuit breaker opens and redirects requests to a fallback mechanism or returns an error response. This helps in isolating the failing component and allows it to recover without affecting the entire system.
Retry Mechanisms: Implementing retry mechanisms for handling transient failures such as network timeouts or temporary unavailability of services. Retrying a failed operation after a certain delay can often lead to successful execution, especially in scenarios where failures are intermittent.
Timeouts: Setting timeouts for service-to-service communication to prevent indefinite waiting and resource exhaustion in case of unresponsive services. Timeouts ensure that services fail fast and gracefully handle failures without causing delays in the entire system.
Bulkheading: Isolating different parts of the system to limit the impact of failures. This involves partitioning services or resources to contain failures within specific boundaries and prevent them from spreading to other parts of the system.
Health Checks and Monitoring: Implementing health checks and monitoring mechanisms to continuously monitor the health and performance of services. Health checks help in identifying unhealthy instances and triggering automated recovery mechanisms such as instance restarts or scaling out.
Graceful Degradation: Designing services to gracefully degrade functionality under high load or failure scenarios. Instead of completely failing, services can degrade their functionality by prioritizing critical operations and deferring non-critical ones.
Immutable Infrastructure: Deploying services using immutable infrastructure principles, where services are replaced with new instances instead of updating existing ones. This ensures that faulty instances can be quickly replaced with healthy ones without in-place upgrades leading to potential downtime.
Communication Way
There are two main approaches to facilitate inter-service communication in Java microservices:
1. Synchronous Communication:
- This method involves a direct request-response pattern, where one service acts as a client and makes a call to another service's API, expecting a response synchronously.
Here are common ways to implement synchronous communication in Java microservices:
RESTful APIs: This popular approach uses HTTP requests and responses to exchange data between services. Java libraries like RestTemplate (deprecated) or WebClient (recommended) simplify sending and receiving RESTful requests, or Using OpenFeign (declarative REST client)
gRPC: This high-performance protocol offers an alternative to REST APIs, providing faster and more efficient communication due to its binary format and efficient encoding. Java libraries like GrpcJava enable gRPC communication in Java microservices.
2. Asynchronous Communication:
- This method employs messaging systems to decouple services and enable loose coupling. Instead of waiting for a direct response, a service sends a message to a central broker, and the receiving service retrieves it asynchronously.
Common ways to implement asynchronous communication in Java microservices:
Message Brokers: Tools like RabbitMQ, Apache Kafka, or Amazon SQS act as intermediaries, allowing services to publish and subscribe to messages without needing to know about each other directly. Java libraries like Spring Kafka or Spring AMQP facilitate interaction with these brokers.
Event-driven architecture: This approach leverages messages to trigger actions within services based on specific events. Services publish events to a central broker, and other services subscribe to these events and react accordingly.
we can use webClient also for asynchronous communication.
Distributed Tracing
Distributed tracing is a technique used to track and observe the flow of requests as they travel through a distributed system. This is particularly important in modern applications built with microservices architectures, where applications are composed of small, independent services that communicate with each other.
Here's a breakdown of what distributed tracing offers:
1. Observability:
It provides visibility into the entire journey of a request, tracing its path through various microservices and infrastructure components involved in fulfilling it.
This allows developers and operations teams to identify performance bottlenecks, errors, and latency issues across the entire system, even when they span multiple services.
2. Debugging:
By visualizing the complete request flow, distributed tracing enables faster debugging of complex issues.
You can pinpoint the exact service or component responsible for a specific problem, leading to quicker resolution times.
3. Monitoring:
It helps monitor the overall health and performance of your distributed system.
You can track metrics like request response times, error rates, and service availability across different services.